Oracle is the database product from the family of products owned by Oracle Corporation. Its most used, versatile, highly scalable and powerful database at present.
It can run on variety of operating system platforms and goes well with approximately all the programming languages.
If you take up learning Oracle database, then SQL and PL/SQL will come along in the journey. A DBA is versed in all these things.
I will here give introduction about Oracle database's architecture and features. It will be good start to start learning Oracle.
- Oracle Architecture
- Oracle Physical Structure
- Oracle Memory Structures
- Background Processes
- Starting up an Oracle database
Oracle Architecture
If you do a search for "oracle architecture", and refer to images, you will get several image results, but a closer look will tell you all of them have similar components in them.
Below is shown a similar image showing general Oracle Architecture.

Oracle database and oracle instance are different entities, and each one can exist independent of another. But the database needs an instance to function and to satisfy user queries.
Database -> Physically stored OS files.
Instance -> Memory structures + Background processes.
In the above image, SGA (System Global Area) and PGA (Private Global Area) represent the memory structures. More info on them later.
DBWn (database writer), LGWR (log writer), PMON (process monitor), SMON ((system monitor), ARCn (archiver process), CKPT (checkpoint process), MMON (memory monitor) etc all are background processes. More info on them later.
Server process is the one which after receiving request from client process, gets data from database and caters to client process.
The database is physical: it consists of files stored on disks. The instance is logical:it consists of in-memory structures and processes on the server.
An instance can be associated with only one database, several instances can connect to a single database (called as Real Application Cluster, which increases availability of database in case one instance fails.).
Physical files consists of : datafiles, control files, redo log files, archived Log Files, parameter file, password file,backup files, Alert and Trace Log Files.
Read on about these in following text.
Oracle Physical Structure TOP
- a) Data Files
A data file is a physical file on disk that was created by Oracle Database and contains data structures such as tables and indexes.
From a physical point of view, a datafile is stored as operating system blocks.
From a logical point of view, datafiles have three intermediate organizational levels: data blocks, extents, and segments. An extent is a set of data blocks that are contiguous within an Oracle datafile. A segment is an object that takes up space in an Oracle database, such as a table or an index that is composed of one or more extents.An oracle data block lies at bottom of logical hierarchy and is a multiple of OS (operating System) block size.
On the top of logical model lies tablespace, which is a logical collection of several data files. A data file belongs to only one tablespace, it cannot span tablespaces.
So the relation goes like as shown in below ER (entity relationship) diagram. The crow's foot notation represents a one-to-many relationship.:

- b) Control Files
- A control file is a file that tracks the physical components of the database. The control file contains locations for other physical files that form the database: the
datafiles and redo log files.
Its a must for a database to operation successfully. A database won't start if any of the control file is missing.
It also contains following key info:
- The name of the database
- When the database was created
- Names and locations of datafiles and redo log files
- Tablespace information
- Datafile offline ranges
- The log history and current log sequence information
- Archived log information
- Backup set, pieces, datafile, and redo log information
- Datafile copy information
- Checkpoint information
- c) Redo log Files
The online redo log is a set of files containing records of changes made to data. They are present in groups called redo log groups. Each group has log files as it members.
These members are written to in a cyclic fashion. After one is filled, Oracle starts writing to next. When it comes back to first, if database is in NOARCHIVELOG mode, the first one is over-written, but if database is in ARCHIVELOG mode, before over-writing the log file, the log file's contents are archived to archive redo log files via ARCn (log archiver) background process. If due to some reason, ARCn process cannot copies its contents to archive redo log files, say for example if the area holding those files, called as FRA (flash recovery area) becomes full, the database hangs till the problem is resolved by making more space available in the FRA.
- d) Archived redo log files
-
As mentioned above too, archived redo log files are actually filled redo log files which are written to FRA location via ARCn background process, when database is in ARCHIVELOG mode.
- e) Database initialization parameter file (init.ora)
This file, called as INIT.ORA or binary server parameter file (SPFILE.ORA), contains set of initialization parameters for startup of database.
Oracle works based upon these parameters, these have global effect, these are similar to registry settings in windows.
Some of these can be altered on the fly (called dynamic parameters), but some cannot be (called static parameters).
Few of the important parameters are:
CONTROL_FILES The control file locations COMPATIBLE This allows you to use latest Oracle release features. e.g. can change it from 10.2 to 11.1 to use all 11.1 features, but can't downgrade DB_NAME The local database name DB_DOMAIN The database domain name (such as us.companyname.com) DB_RECOVERY_FILE_DEST The location of the database flash recovery area (FRA) DB_RECOVERY_FILE_DEST_SIZE FRA size in maximum size in total bytes DB_BLOCK_SIZE The database block size in bytes IFILE Embed another init file. e.g. ifile=config.ora. In this, you can store comon init params for several instances. 3 Levels on nesting allowed and there can be multiple IFILE paramenters in a single init file INSTANC_NAME Same as DB_NAME in single instance environment. Can associate multiple instances to single DB_NAME in RAC environment LOG_ARCHIVE_DEST The log archive destination MEMORY_TARGET Target memory size that is automatically allocated to SGA and PGA components NLS_LANGUAGE The National Language Support (NLS) language specified for the database NLS_TERRITORY The National Language Support territory specified for the database SHARED_SERVERS The minimum number of database shared servers SERVICE_NAME One or more names by which clients can connect to the instance - spfile$ORACLE_SID.ora
- spfile.ora
- init$ORACLE_SID.ora
- init.ora
- f) Password file
When database is not started and DBA wants to start it, then Oracle must first authenticate the DBA. As database cannot be accessed, when its down, for authentication, there must be a way to authenticate DBA outside the database. This is done via password file, which stores the password for privileged user like DBA in binary format. This type of authentication is called as password file authentication.
For password file authentication, the file is created with the ORAPWD utility. Users are added by SYS or by those having SYSDBA privileges.
A password file might be shared with several databases present on the server or can be exclusive to a particular database.
- g) Backup Files
If you have a database, you should take its backup periodically, as per a well-defined backup strategy. The resulting files are called as backup files.
The backup files can be generated via general OS level copy commands or via Oracle's proprietary tool for backup called as RMAN. Learn more about RMAN tool here.
These backup files can later on be used for database recovery purpose.
Note: Oracle Backup and Recovery concepts are a must to learn if you want to be a successful Oracle DBA.These concepts require both theoretical and practical hands-on knowledge to master them.
- h) Alert and Trace Log Files
During database startup, shutdown, upon occurrence of some critical error like FRA being full or some Oracle internal error, information is written to alert log file. This is found in file location specified by parameter BACKGROUND_DUMP_DEST.
Any ALTER DATABASE or ALTER SYSTEM commands issued by the DBA are recorded.
Operations involving tablespaces and their datafiles are recorded here too, such as adding a tablespace, dropping a tablespace, and adding a datafile to a tablespace.
Error conditions, such as tablespaces running out of space, corrupted redo logs, and so forth, are also recorded here—all critical conditions.Trace files (*.trc files) are created for background processes in BACKGROUND_DUMP_DEST and for user sessions in USER_DUMP_DEST directory.
Trace files for background processed contains informational and error related messages w.r.t. background processes.
Trace files for user processes are created in two situations: They are created when some type of error occurs in a user session because of a privilege problem, running out of space, and so forth. Or a trace file can be created explicitly with this command:
ALTER SESSION SET SQL_TRACE=TRUE;
Trace information is generated for each SQL statement that the user executes, which can be helpful when tuning a user’s SQL statement.
To trace your particular session, enable/disable trace via command: ALTER SESSION SET SQL_TRACE = true/false;
For Tracing entire database, use: ALTER SYSTEM SET sql_trace = true/false SCOPE=MEMORY;As sysdba, you can trace any specific user session via following steps:
- Set ORACLE_SID, ORACLE_HOME and PATH variables.
- Verify that TIMED_STATISTICS and TIMED_OS_STATISTICS are set to true otherwise many statistics will not get logged in generated trace files.
- Get the SID and SERIAL# for the process you want to trace via v$session.
- ALTER SYSTEM SET timed_statistics = true;
- Enable tracing for the session: execute dbms_system.set_sql_trace_in_session(8, 13607, true);
- Now ask user to run his query or to be tested operation. Ask user to logout of session or app so that all information is logged in trace file completely.
- Disable tracing for the session: execute dbms_system.set_sql_trace_in_session(8,13607, false);
- Can check the name of generated trace file via following sample query:
select b.username||'@'||machine||'#'||osuser||'#'||b.program||'#'||b.sql_trace, 'exec sys.dbms_system.set_sql_trace_in_session (' ||b.sid||',' ||b.serial#||',TRUE);' as enable_trace, 'exec sys.dbms_support.start_trace_in_session ('||b.sid||','||b.serial#||',waits=>TRUE, binds=>FALSE);' as enable_trace2, b.sid S,b.serial# SR,b.program,c.value || '/' || d.instance_name || '_ora_' || a.spid || '.trc' trace_file_is_here, b.logon_time,b.status,b.sql_trace from v$process a, v$session b, v$parameter c, v$instance d where a.addr = b.paddr and c.name = 'user_dump_dest' and b.username is not null and b.type <> 'BACKGROUND' and b.osuser not in ('oracle') order by b.logon_time desc; - Then via tkprof utility, convert the trace file into human readable format. For example:
tkprof input_trace_ora_15728728.trc output_trace.txt sys=no explain=\" / as sysdba\"
Server parameter file (spfile.ora)
More than half of the initialization parameters in Oracle are dynamic, i.e. they can be changed by ALTER SYSTEM command while the instance is still running. But problem with this approach is that once the instance is restarted, those daynamically changes values get vanished. So DBA must remember to change them in init.ora file before restarting the instance.
Server parameter file gives solution to this problem and with its use any dynamic parameter changed via ALTER SYSTEM while instance is running is stored in server parameter file also. This file is binary and only Oracle can edit it. It has all the parameters from init.ora file. So all dymanic changes made to initialization parameters can be permanently stored in the spfile.
By default, Oracle looks for initialization file in following order in the default directory:
Refer to V$SPPARAMETER dynamic view to check initialization parameters when using spfile.
To start an instance with spfile, use STARTUP command with an init.ora file containing only one parameter named spfile.
cat init.ora spfile = '/path/to/spfile.ora' STARTUP pfile='/path/to/init.ora'
Oracle Memory Structures TOP
I have here tried to explain about the various memory areas in as practical manner as I can. Read on.....

All below mentioned areas belong to SGA.
If we fire a SELECT statement, database buffer cache (one of the Oracle's memory structure) is searched for asked data. If data is found there, its said a hit, the desirable and efficient case.
If not found in DB buffer cache, its a miss and data is fetched from disk, then brought into DB buffer cache, and passed on to user process by server process. Clearly, this is less efficient and least desired as getting data from disk is slow compared to getting it from memory.
When we fire an UPDATE statement, data to be modified is fetched into DB buffer cache (if its not already there), then data blocks are modified in buffer cache only. This modified data stays in buffer cache, till DBWRn (DB writer) background process wakes up and flushes it to physical data files on the disk.
When a change is made, a log entry, called as change vector is also generated and put into redo log buffer cache (another Oracle's memory structure). This change data stays there till LGWR (log writer) background process wakes up and flushes this data to physical online redo log files.
Shared pool memory structure consists of two major sub-caches: the library cache and the data dictionary cache.
The SQL statements that we fire, their plans are held in library cache, so as to decrease parsing cost when same statements are fired again.
If the library cache is sized too small, then frequently used execution plans can be flushed out of the cache, resulting into frequent reloads of such SQL statements into the library cache. This decreases efficiency of overall query execution.
Similarly, there is dictionary cache which holds data dictionary related information. Data Dictionary is a collection of database tables, owned by the SYS and SYSTEM schemas, which contain the metadata about the database, its structures, and the privileges and roles of database users. Means data dictionary contains info about database tables, like table names, column names, column data-type, column length etc. It also contains privilege information, like if some user has SELECT or UPDATE access on a database table.
When we fire a SELCT statement, that statement is first parsed, i.e. data dictionary is referred to check if table name is correct and tables does exists, if selected columns are correct, if the user firing select query has SELECT privilege or not. If this data dictionary related info is stored in a memory area (i.e. dictionary cache), Oracle won't have to refer to physical disk drive for that, means it will be an efficient thing to do.
If the data dictionary cache is too small, requests for information from the data dictionary will cause extra I/O to occur; these I/O-bound data dictionary requests are called recursive calls and should be avoided by sizing the data dictionary cache correctly.
All above mentioned memory areas are mandatory ones.
Oracle utilizes the memory(RAM) present on server for holding its memory structures. There are several things that are present in the memory area related to instance, like the Oracle executable code, session information, individual processes associated with the database, and information shared between processes (such as locks on DB objects). Memory structures also contain user and data dictionary SQL statements, along with cached data (like data blocks), that is eventually permanently stored on disk. The data area allocated for an Oracle instance is called the System Global Area (SGA).
In addition, an area called the Program Global Area (PGA) is private to each server and background process; one PGA is allocated for each user session or server process.
The large pool memory area is an optional area of the SGA. It is used for distributed transactions, i.e. that interact with more than one database, for processes performing parallel queries, and RMAN parallel backup and restore operations.
Like shared pool caches the SQL and PL/SQL code for re-use (to increase efficiency), similarly java pool memory area is used by the Oracle JVM (Java Virtual Machine) for storing all Java code and data within a user session.
Program Global Area TOP
The PGA is an area of memory allocated privately for each server and background process. The configuration of the PGA depends on the connection configuration of the Oracle database: either shared server or dedicated server.
In a shared server configuration, multiple users share a connection to the database, minimizing memory usage on the server but increasing the response time for user requests. In a shared server environment, the SGA holds the persistent session information for a user instead of the PGA. Shared server environments are ideal for a large number of simultaneous connections to the database with infrequent or short-lived requests.
In a dedicated server environment, each user process gets its own connection to the database; the PGA contains the session memory for this configuration. The PGA also includes a sort area that is used whenever a user request requires a sort, bitmap merge, or hash join operation.
Oracle Background Processes TOP
There are several background processes in Oracle, each of them performs a specific task.
SMON : In the case of a system crash or instance failure, due to a power outage or CPU failure, SMON, the system monitor process, performs crash recovery by applying the entries in the online redo log files to the datafiles. One of SMON’s routine tasks is to coalesce the free space in tablespaces on a regular basis if the tablespace is dictionary managed (which should be rare or nonexistent in an Oracle 11g database).
PMON : If a user connection is dropped or a user process otherwise fails, PMON, the process monitor, does the clean-up work. It cleans up the database buffer cache along with any other resources that the user connection was using. For example, suppose a user session is updating some rows in a table, placing a lock on one or more of the rows, and it suddenly fails due to some reason. Within milliseconds, PMON will detect this and will :
- Roll back the transaction that was in progress when the power went out.
- Mark the transaction’s blocks as available in the buffer cache.
- Remove the locks on the affected rows in the table.
- Remove the process ID of the disconnected process from the list of active processes.
PMON does dynamic registration of instance information with the listeners. This removes DBA's overhead to do registration manually. It dynamically provides information about an instance like database services provided by the database, the name of the database instance associated with the services and its current and maximum load, and information on the service handlers (dispatchers and dedicated servers).
DBWn : The database writer process writes new or changed data blocks (known as dirty blocks) in the DB buffer cache to the physical datafiles on the disk. The letter 'n' in DBWn can have 20 values to the max, means up-to 20 DBWn processes can be started, DBW0 through DBW9 and DBWa through DBWj.
LGWR :Log Writer process writes change vectors from log buffer cache to physical online redo log files on disk, thereby completing a transaction. A transaction is not considered complete until LGWR successfully writes the redo information, including the commit record, to the redo log files. In addition, the dirty buffers in the DB buffer cache cannot be written to the datafiles by DBWn until LGWR has written the redo information. Think about this : LGWR is one of the most active processes in an instance with heavy DML activity.
LGWR writes to the redo logs under the following circumstances:
- Every 3 seconds.
- When the redo log buffer is one-third full.
- When the DBWn process signals that redo records need to be written to disk.
- Also, the LGWR writes a commit record to the redo log following the committing of each transaction.
What happens when we do a Commit?
When we issue a COMMIT command, the comitted change is NOT immediately written to the disk to make it permanent. Instead LGWR puts a commit record in the redo log buffer and immediately writes that record to the redo log file along with the redo entries pertaining to the committed transaction.
Each comitted transaction is assigned a SCN (System Change Number), which the log writer records in the redo log. The database makes use of these SCNs during a database recovery. So transaction is committed but the changed data buffers are not immediately written to the disk, and get written at some appropriate time. This technique of indicating a successful commit ahead of the actual writing of the changed data blocks to disk is called the fast commit mechanism.
ARCn : If the database is in ARCHIVELOG mode, then the archiver process, or ARCn, copies redo logs to one or more destination directories, devices, or network locations whenever a redo log fills up and redo information starts to fill the next redo log in sequence. Optimally, the archive process finishes copying a filled redo log before it is needed again; otherwise, serious performance problems occur — think about this, users cannot complete their transactions until the entries are written to the redo log files, and the redo log file is not ready to accept new entries because it is still being written to the archive location.
There are 3 potential solutions to this problem: increase the size of redo log files, increase the number of redo log groups, and increase the number of ARCn processes. Up to 10 ARCn processes can be started for each instance.
CKPT :The checkpoint process, or CKPT, helps to reduce the amount of time required for instance recovery. During a checkpoint, the CKPT process flushes contents of redo log buffer to redo log files, writes a checkpoint record (a list of all active transactions and the address of the most recent log record for those transactions) to the log file, tells DBWn to write the dirty data in the memory buffers to disk, updates the header of the control file and the datafiles to reflect the last successful System Change Number (SCN). The purpose of CKPT is to synchronize the buffer cache information with the information on the database disks.
A checkpoint occurs automatically every time one redo log file fills and Oracle starts to fill the next one in a round-robin sequence.
The DBWn routinely write dirty buffers to advance the checkpoint from where instance recovery can begin, thus reducing the Mean Time to Recovery (MTTR).
Because DBWn writes all modified blocks to disk at checkpoints, the more frequent the checkpoints, the less data will need to be recovered when the instance crashes. However, checkpointing involves an overhead cost. Oracle lets you configure the database for automatic checkpoint tuning, whereby the database server tries to write out the dirty buffers in the most efficient way possible, with the least amount of adverse impact on throughput and performance.
MMAN :Memory Manager coordinates the dynamic re-sizing of SGA memory areas as per the workload.
Below image shows various background processes:
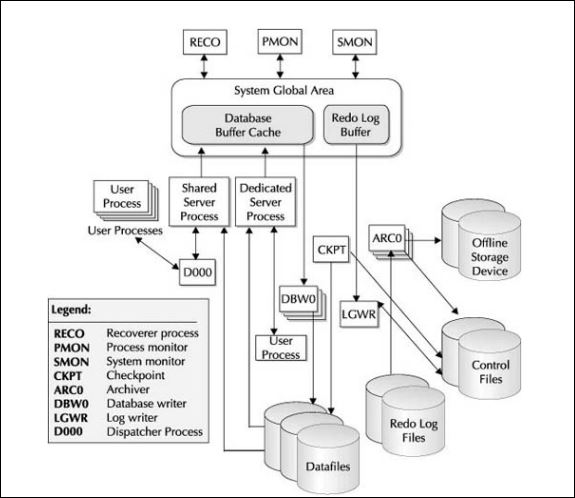
Starting up an Oracle database TOP
You can startup Oracle database in various modes. Below are various commands that can be issued:
- a) STARTUP NOMOUNT
- b) STARTUP MOUNT
- c) STARTUP OPEN
Below image shows various startup modes and their description:

Refer to this Oracle architecture related file for more info.
Thanks...
TOP